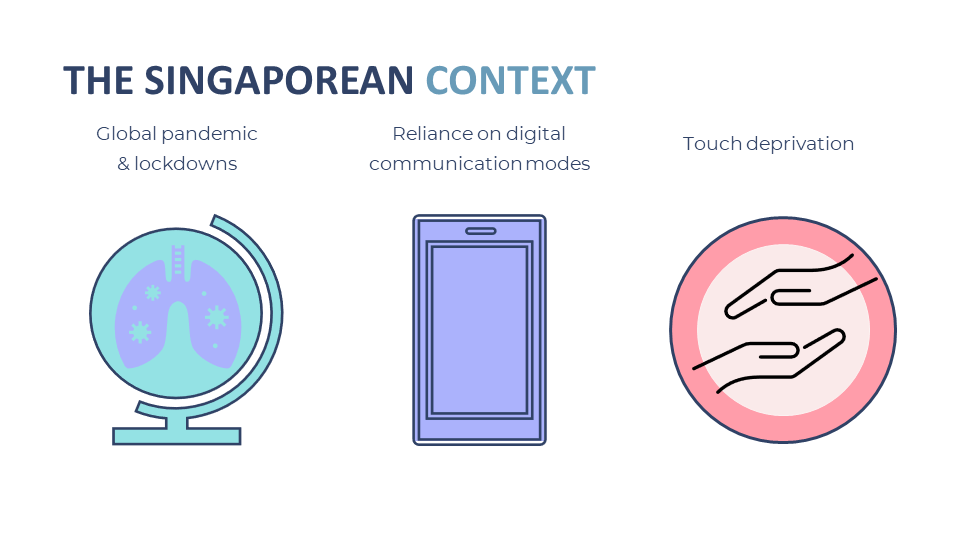
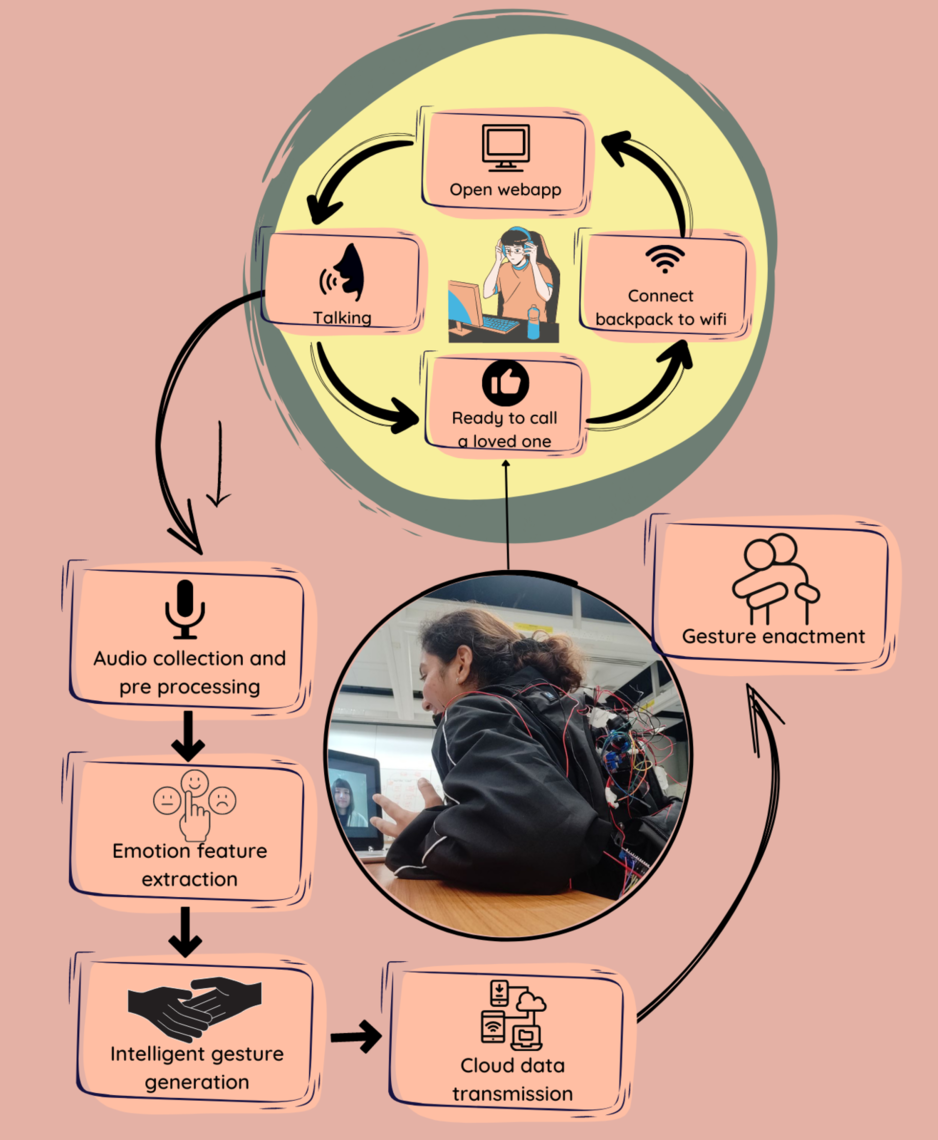
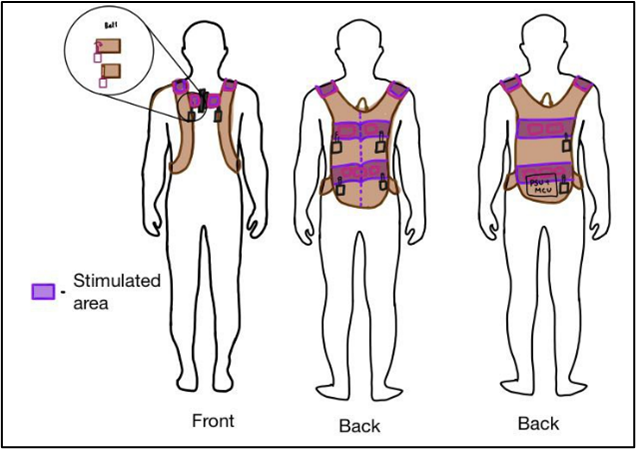
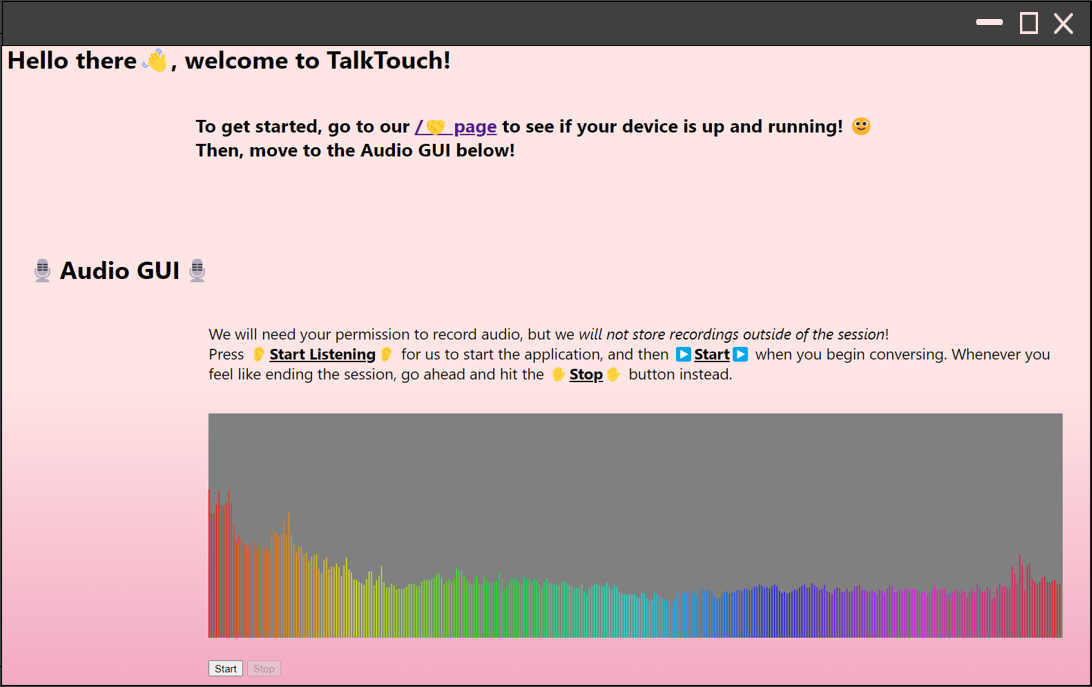
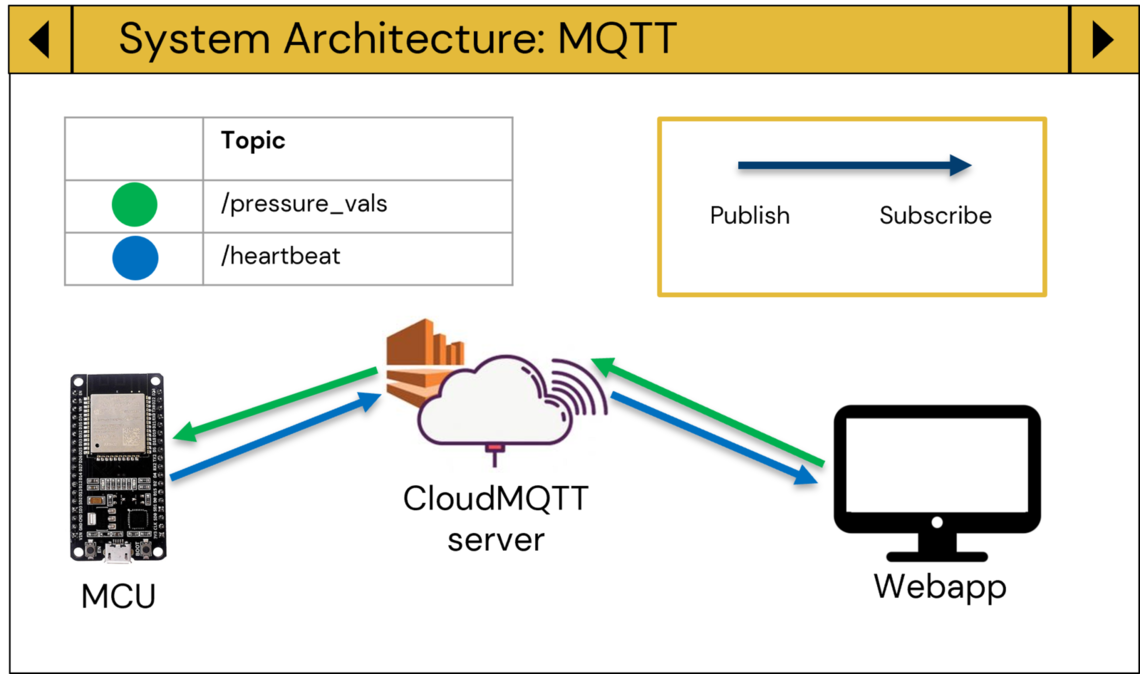
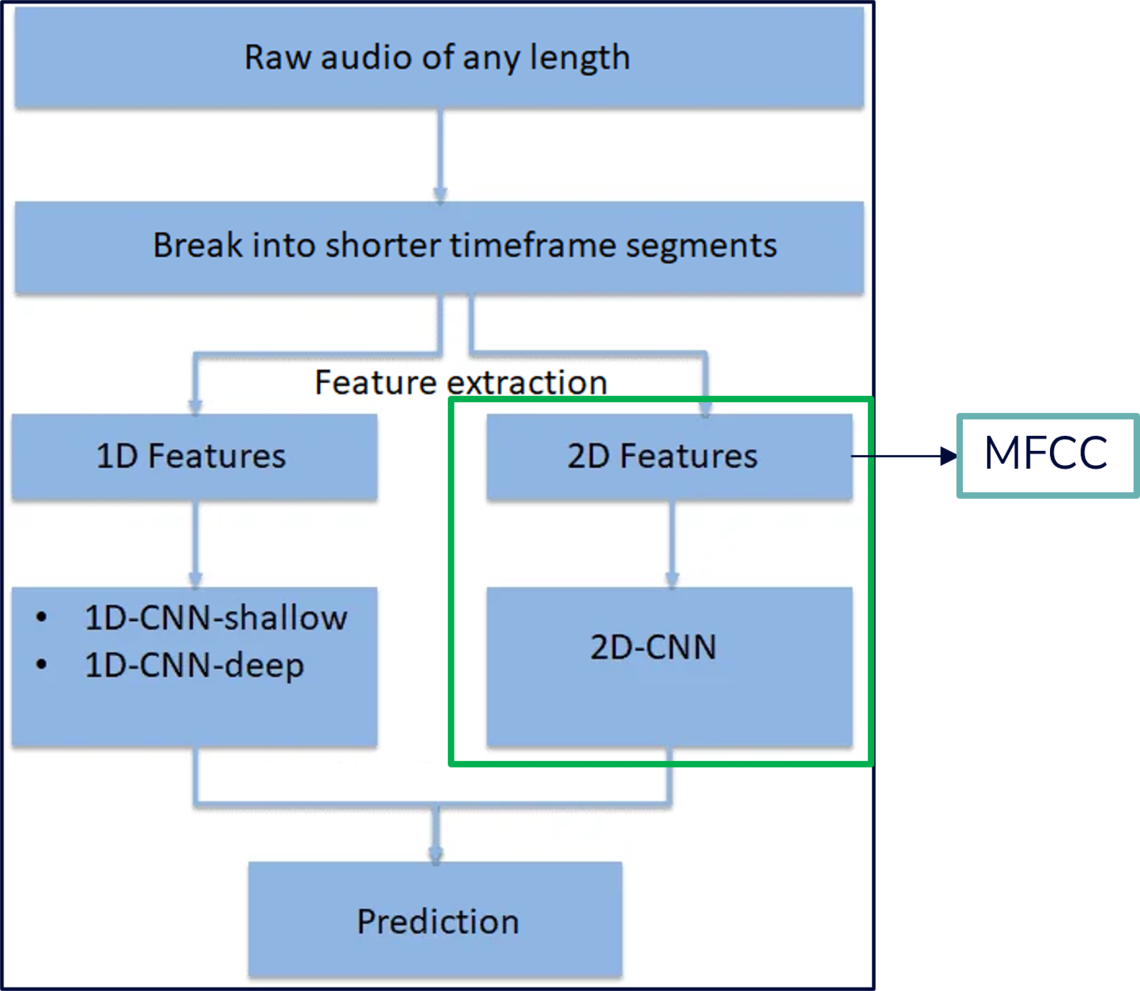
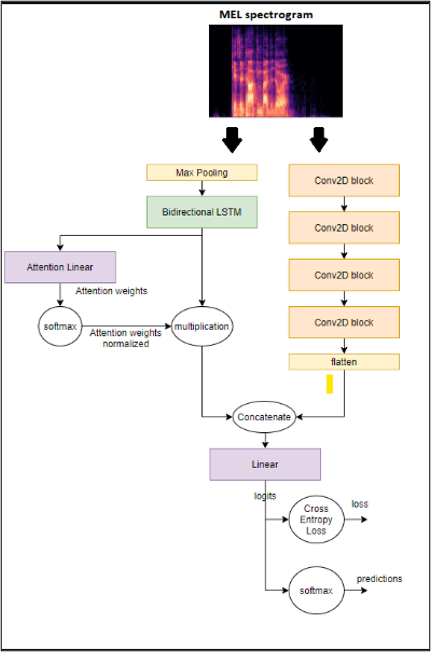
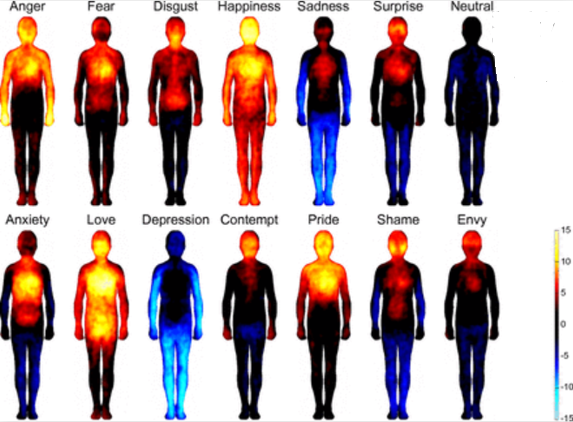
CAPSTONE DESIGN SHOWCASE 2022
-
DAYS
-
HOURS
-
MINUTES
-
SECONDS
COMING SOON


Team members
Jeremy Surjoputro (EPD), Maddula Akshaya (EPD), Akshaya Rajesh (EPD), Wong Kai-En Matthew Ryan (ISTD), Ang Sok Teng Cassie (ISTD)
Instructors:
Writing Instructors:
Teaching Assistant:
 Jeremy Surjoputro
Engineering Product Development
Jeremy Surjoputro
Engineering Product Development
 Maddula Akshaya
Engineering Product Development
Maddula Akshaya
Engineering Product Development
 Akshaya Rajesh
Engineering Product Development
Akshaya Rajesh
Engineering Product Development
 Wong Kai-En Matthew Ryan
Information Systems Technology and Design
Wong Kai-En Matthew Ryan
Information Systems Technology and Design
 Ang Sok Teng Cassie
Information Systems Technology and Design
Ang Sok Teng Cassie
Information Systems Technology and Design
Jeremy Surjoputro
Engineering Product Development
Maddula Akshaya
Engineering Product Development
Akshaya Rajesh
Engineering Product Development
Wong Kai-En Matthew Ryan
Information Systems Technology and Design
Ang Sok Teng Cassie
Information Systems Technology and Design